

What is the “Non-Indexable Pages” Issue in the Site Audit?
A “Non-Indexable Pages” issue in a site audit typically refers to web pages on a site that search engines cannot index. This means that search engines cannot include these URLs in their search results. There are several reasons why a site might be non-indexable, including:
Robots.txt Restrictions
The robots.txt file can be configured to disallow search engine crawlers from accessing certain URLs or directories.
Meta Robots Tags
Pages may have meta tags like <meta name=”robots” content=”noindex”> which instruct search engines not to index the URL.
HTTP Status Codes
Pages returning certain HTTP status codes (e.g., 404 Not Found, 403 Forbidden, 500 Internal Server Error) are not indexable.
Canonical Tags
If a page has a canonical tag pointing to another URL, search engines may index the canonical URL instead of the current one.
Noindex in X-Robots-Tag
HTTP headers can include a noindex directive, preventing pages from being indexed.
Crawl Budget
If a site has a large number of pages, search engines may prioritize which URLs to crawl and index, potentially leaving some pages unindexed.
Duplicate Content
URLs with duplicate content may not be indexed if search engines determine they are not significantly different from other pages.
Blocked by Firewall or Authentication
Pages that require authentication or are behind a firewall cannot be crawled and indexed by search engines.
Poor Page Quality
URLs with very little content, poor quality content, or content that violates search engine guidelines might not be indexed.
JavaScript Issues
Pages that rely heavily on JavaScript for content rendering might face indexing issues if search engines cannot execute the JavaScript properly.
Identifying and resolving non-indexable URLs in a site audit is crucial for improving a site’s visibility and performance in search engine results. Addressing these issues typically involves adjusting configurations, improving content, and ensuring that search engine crawlers can access and understand the pages on the site.
How to Check the Issue
Indexation can be prohibited using several methods. Each of them should be checked separately.
1. Meta Robots
Using any browser is enough to check the issue. Open the source code of the flawed page. To do this, click the right mouse button at any spot of the page and choose “browse the code” option, or apply an online tool.
Find a directive. If the value of the content = noindex, there is an issue at the page.
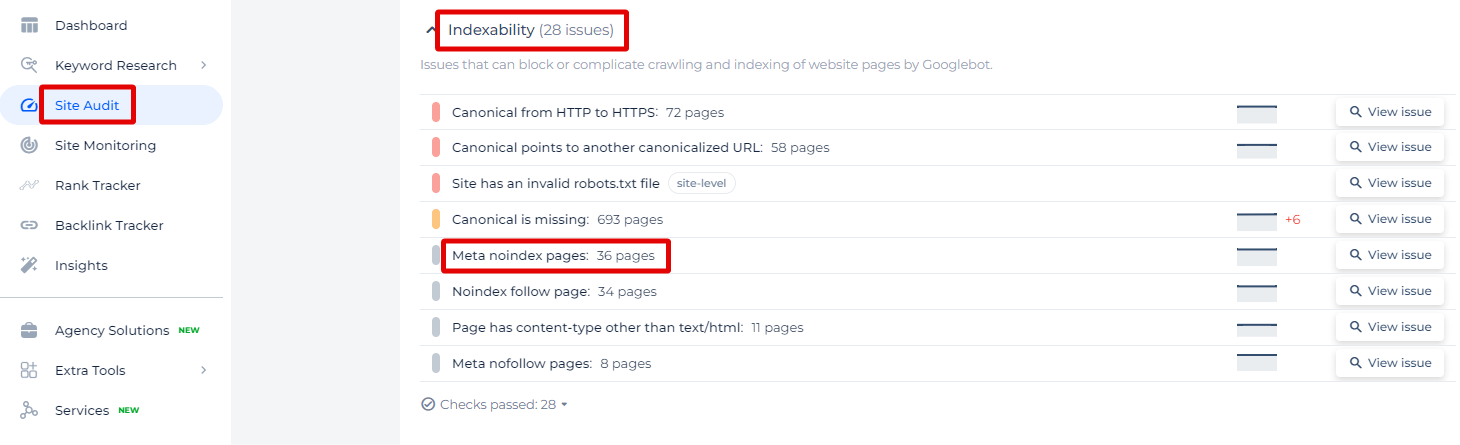
In the provided screenshot from the Sitechecker SEO tool, the focus is on identifying pages with the “Meta noindex” tag. This feature is vital for website owners and SEO specialists to understand which pages on their site are explicitly instructed not to be indexed by search engines through the meta noindex directive.
2. X-Robots-Tag
To check the server’s response, use a tool Redbot or any similar tool. The presence of an X-Robots-Tag: noindex in the server’s response means there is an issue at the page.
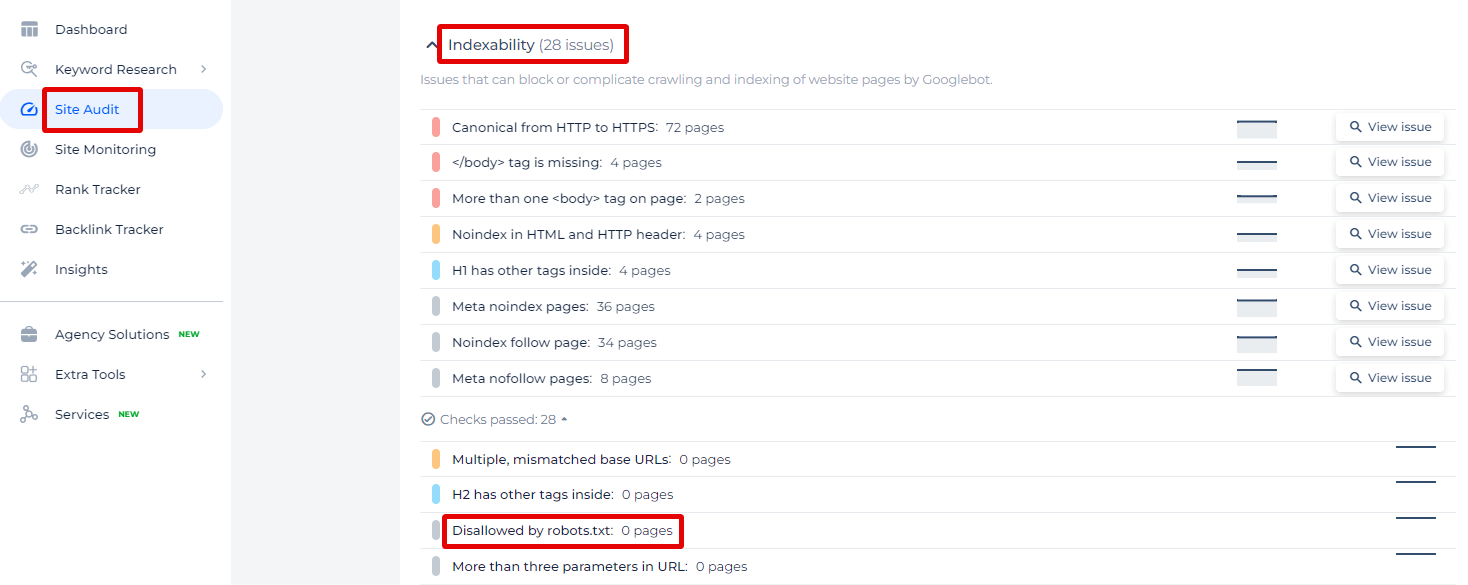
In the Sitechecker SEO tool, you can see the specific issue called “Disallowed by robots.txt.” This feature of the tool is crucial for webmasters and SEO specialists who need to understand which URLs on their website are blocked from being indexed by search engines due to rules set in the robots.txt file.
Spot and Fix Non-Indexable Pages to Boost Your SEO!
Use our Site Audit Tool to uncover and resolve non-indexable pages and optimize your site.
How to Fix This Issue
To fix the “Non-Indexable Pages” issue identified in a site audit, you can follow these steps:
1. Review Robots.txt File
Ensure that your robots.txt file isn’t disallowing access to important pages or directories. Modify the file to allow search engine crawlers to access URLs that should be indexed.
2. Inspect Meta Robots Tags
Check for meta tags like <meta name=”robots” content=”noindex”> on pages that should be indexed. Remove or change the noindex directive to index for URLs that need to be indexed.
3. Check HTTP Status Codes
Use tools to identify pages returning 4xx or 5xx status codes. Correct the issues causing these errors, such as broken links, missing files, or server misconfigurations.
4. Evaluate Canonical Tags
Ensure that canonical tags are correctly pointing to the intended canonical versions of your URLs. Each page should ideally point to itself with its canonical tag unless a different URL is the canonical version.
5. X-Robots-Tag HTTP Header
Ensure that HTTP headers do not include X-Robots-Tag: noindex for pages that should be indexed. Modify headers to allow indexing of the necessary URLs.
6. Manage Crawl Budget
Prioritize important pages for crawling and ensure they are easily discoverable by search engines. Improve internal linking structure to help search engines discover and index important pages.
7. Address Duplicate Content
Ensure each page has unique, valuable content. Use canonical tags or redirects to consolidate duplicate content into a single URL.
8. Resolve Authentication and Firewall Issues
Configure authentication and firewall settings to allow search engine bots to access public pages. Keep noindex tags on URLs that should remain private and inaccessible to search engines.
9. Improve Page Quality
Add meaningful, high-quality content to thin or low-quality pages. Ensure pages meet search engine guidelines for quality and relevance.
10. Address JavaScript Issues
Consider using server-side rendering or static site generation for JavaScript-heavy sites to ensure content is accessible to search engines.




