De robots.txt file levert belangrijke informatie aan de zoeksystemen tijdens het scannen van het internet. Voordat de pagina’s van jouw website bekeken worden, kijken de zoekrobots eerst naar dit bestand. Door deze procedure wordt de efficiency van het scannen verhoogd. Op deze manier help je de zoeksystemen om de meest belangrijke data van jouw website eerst te scannen. Dit is echter alleen mogelijk wanneer je de robots.txt goed ingesteld hebt. Net als de richtlijnen van de robots.txt file generator, is de no-index instructie in de meta tag robots niet meer dan alleen een aanbeveling voor de robots. Dit betekent dat er geen garantie is dat gesloten pagina’s niet geïndexeerd worden en niet in de index opgenomen zullen worden. Garanties kunnen niet gegeven worden op dit gebied. Wil je sommige gedeeltes van de website volledig afsluiten voor het indexeren, dan kun je deze bestanden vergrendelen met een wachtwoord.
Main Syntax
User-Agent: de robot waarvoor de volgende regels toegepast worden (bijvoorbeeld, “Googlebot”)
Disallow: de pagina’s die je af wilt sluiten voor toegang (wanneer je elke keer op een nieuwe regel begint, kun je een groot aantal gelijke directieven ingeven) Iedere groep User-Agent / Disallow moet gescheiden worden door een witregel. Maar niet-lege strings moeten niet voorkomen binnen de groep (tussen User-Agent en de laatste directieve Disallow).
Hash mark (#) kan gebruikt worden wanneer er behoefte is om commentaren in te kunnen voegen in de robots.txt file voor de huidige regel. Alles wat achter de hashtag staat, wordt genegeerd. Werk je met een robots.txt generator, dan kan dit toegepast worden voor heel de regel en na alle directieven. Catalogi en bestandsnamen zijn te gebruiken in het register: het zoeksysteem accepteert «Catalog», «catalog», en «CATALOG» als verschillende directieven.
Host: wordt gebruikt voor Yandex om de spiegelwebsite aan te geven. Dit is waarom je bij het gebruik van een 301 redirect om twee websites aan elkaar te plakken, je dit niet hoeft te doen in de file robots.txt (op de duplicate website). Yandex vindt het commando op de website die vast moet zitten.
Crawl-delay: je kunt de snelheid van het doorzoeken van de website limiteren wat handig is wanneer je grote aantallen bezoekers ineens op de website hebt. Deze optie gebruik je door dit toe te voegen aan de robots.txt file, zodat je problemen met het extra verkeer kunt voorkomen, van de verschillende zoekmachines die alle informatie op jouw website doorzoeken.
Regular phrases: tom de directieven meer flexibel op te zetten, kun je de onderstaande twee symbolen gebruiken:
* (ster) – geeft een rij symbolen aan,
$ (dollarteken) – laat het einde van een regel zien.
Voorbeelden van het gebruik van een robots.txt generator
Indexeren van heel de website onmogelijk maken
User-agent: *
Disallow: /Deze instructie moet ingegeven worden wanneer je een nieuwe website maakt en sub-domeinen gebruikt die toegang verschaffen. Vaak wanneer er gewerkt wordt aan een nieuwe website, vergeten de web ontwikkelaars om een gedeelte van de website af te sluiten voor indexering en als gevolg komt er een complete kopie via de index systemen. Wanneer een fout zoals dit gemaakt is, moet het master domein een 301 redirect pagina krijgen. Robots.txt generator kan daarvoor heel handig zijn!
De volgende constructie staat het indexeren van de hele website TOE:
User-agent: *
Disallow:
Indexeren van een bepaalde map onmogelijk maken
User-agent: Googlebot
Disallow: /no-index/
Bezoek van een bepaalde pagina onmogelijk maken voor een bepaalde robot
User-agent: Googlebot
Disallow: /no-index/this-page.html
Indexeren van bepaalde types bestanden onmogelijk maken
User-agent: *
Disallow: /*.pdf$
Een bepaalde web robot toegang verlenen voor een bepaalde pagina
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Website link naar de sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Bijzonderheden die je in de gaten moet houden bij het gebruik van deze richtlijn wanneer je de website constant aanvult met unieke content:
- Voeg geen link toe naar de sitemap in de robots.txt generator;
- Kies een niet-standaardnaam voor de sitemap in plaats van sitemap.xml (bijvoorbeeld mijn-nieuwe-sitemap.xml en voeg deze vervolgens toe aan het zoeksysteem door webmasters te gebruiken;
omdat veel oneerlijke webmasters de content van andere websites ontleden en dit vervolgens gebruiken voor hun eigen projecten.
Controleer uw webpagina's op indexeringsstatus Detecteer alle niet-geïndexeerde URL's en ontdek welke webpagina's mogen worden gecrawld door bots van zoekmachines
Wat is beter: robots txt generator of noindex?
Wanneer je sommige pagina’s uit wilt sluiten van indexeren, dan is noindex in de meta tag robots meer aan te bevelen. Om dit te implementeren, voeg je de volgende meta tag in de sectie van de pagina toe:
<meta name=”robots” content=”noindex,follow”>Met deze aanpak zorg je ervoor dat:
- Indexeren van een bepaalde pagina bij volgend bezoek van een web robot niet gebeurt (je hoeft de pagina niet handmatig te verwijderen met webmasters);
- De linkkracht van de pagina overgebracht wordt.
Robots txt file generator is beter bij het gebruik van de volgende pagina’s:
- administratieve pagina’s van jouw website;
- zoekdata op de site;
- pagina’s voor registratie/autorisatie/resetten van het wachtwoord.
Welke hulpmiddelen kun je gebruiken voor het controleren van de robots.txt file?
Wanneer je een robots.txt genereert, dan moet je controleren of je geen fouten gemaakt hebt. De robots.txt check van de zoekmachines kunnen je helpen bij het uitvoeren van deze taak:
Log in op het account waaraan de website gekoppeld is, ga naar
Crawl en vervolgens naar robots.txt Tester.
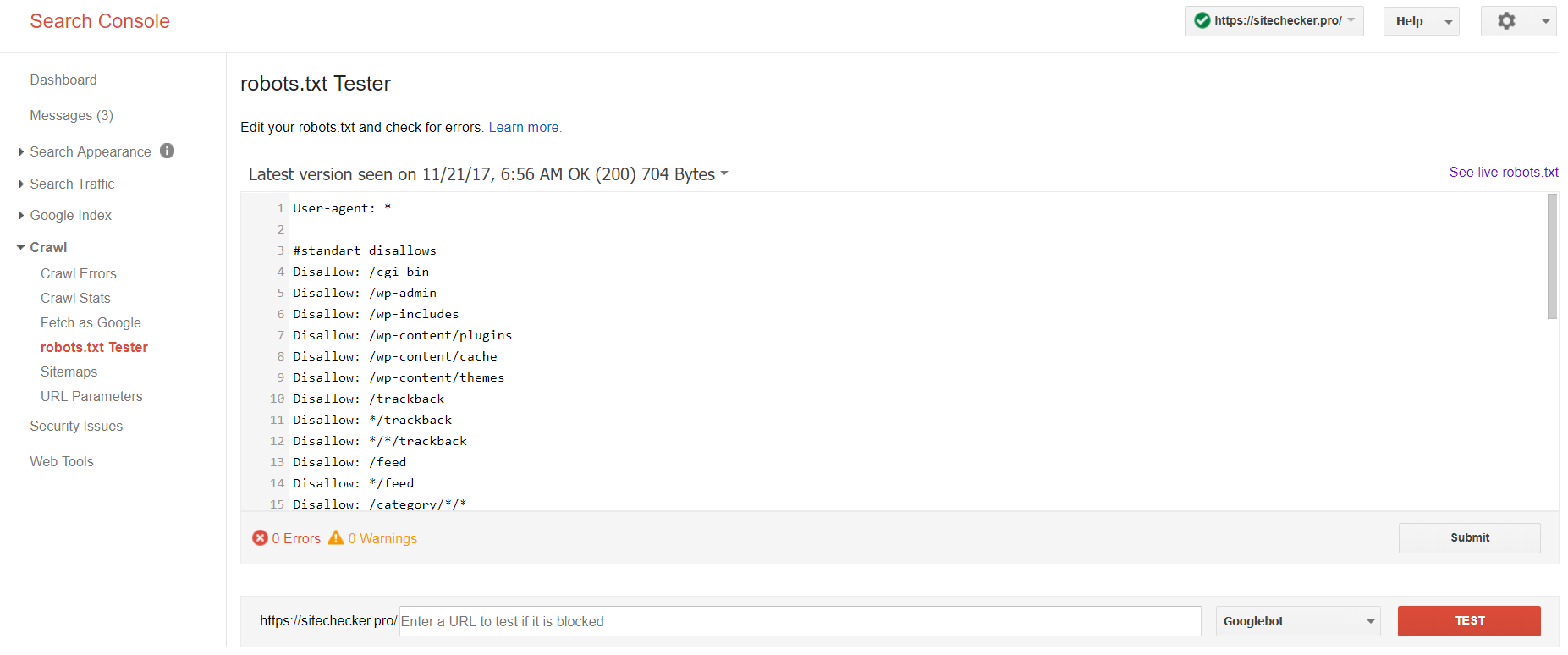
Deze robot txt test maakt het mogelijk om:
- alle fouten en mogelijke problemen in een keer op te zoeken;
- te checken op fouten en direct aanpassingen te doen zodat je de nieuwe file direct op de website kunt zetten zonder extra verificaties;
- te toetsen of je de pagina’s goed afgesloten hebt die je niet wilt laten indexeren en of de pagina’s die wel geïndexeerd moeten worden toegankelijk zijn op de juiste manier.
Log in op het account waar de huidige website aan gekoppeld is, ga naar Tools en vervolgens naar Robots.txt analysis.
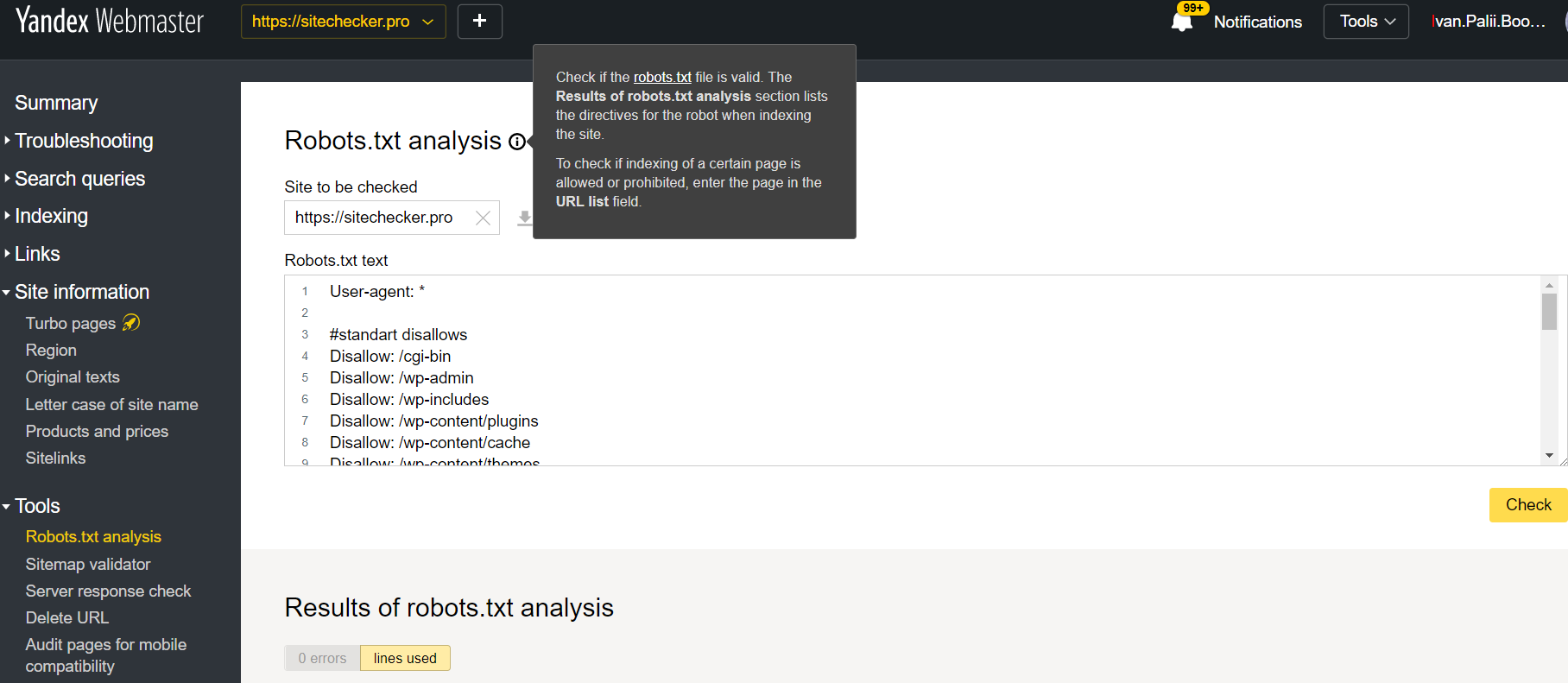
Deze tester heeft nagenoeg dezelfde mogelijkheden voor verificatie als de tester die hierboven beschreven is. De verschillen zijn de volgende:
- hier hoef je niet te autoriseren dat je de rechten hebt voor een website die een rechtstreekse verificatie heeft voor de robots.txt file;
- je hoeft niet elke pagina in te voeren: de complete lijst met alle pagina’s kan gecontroleerd worden met een sessie;
- je kunt er zeker van zijn dat Yandex jouw instructies duidelijk begrepen heeft.