В словаре SEO-специалистов часто можно услышать о таком понятии, как “дружественность сайта к поисковым системам”. Что это значит? Процесс сканирования и индексирования сайта это достаточно затратный процесс для всех поисковых систем, особенно с таким ростом количества сайтов и страниц, как происходит сейчас. Чем дороже процесс по ресурсам, тем больше лимитов и жестких правил устанавливают поисковики. Понимание того, по каким правилам работают поисковые роботы (в частности, Googlebot) поможет постепенно сделать свой сайт “дружественным” для поисковиков. А это помогает быстрее индексировать новые и обновленные страницы, быстрее находить ошибки и т.д.
Что такое Googlebot?
Поисковые роботы (например, Googlebot) – это роботы, которые сканируют веб-страницы и добавляют их индекс. Если код на странице дает боту команду на индексирование, тогда он добавляет эту страницу в индекс, и только тогда она становится доступной пользователям. Очень хорошо этот процесс описан в этом руководстве Google. Ключевыми правилами сканирования, являются четыре следующие шага:
Если страница высоко ранжируется, поисковый робот Google будет тратить больше времени на её сканирование.
Здесь мы можем поговорить о «краулинговом бюджете», представляющем собой точное количество времени, затрачиваемого веб-роботами на сканирование определенного сайта: чем более авторитетна веб-страница, тем больший бюджет она получит.
Google бот постоянно сканирует сайт
Вот что об этом говорит Google: «Поисковый робот Google не имеет доступа к сайту чаще, чем один раз в секунду». Это означает, что сайт находится под постоянным контролем веб-пауков, если у них есть доступ к нему. Сегодня многие SEO специалисты спорят о так званой «скорости обхода» и пытаются найти оптимальный способ обхода сайта роботом, чтобы получить высокий уровень ранжирования. Тем не менее, «скорость обхода» – это всего лишь скорость запросов поискового робота Google, а не повторение сканирования. Вы даже можете изменить этот показатель самостоятельно с помощью Webmasters Tools. Огромное количество внешних ссылок, наличие ссылок с 404 ошибкой, уникальность и упоминания в соцсетях влияют на вашу позицию в результатах поиска. Также важно уточнить, что веб-пауки не сканируют каждую страницу непрерывно, поэтому намного выгоднее сразу создавать полезный и уникальный контент.
Файл Robots.txt – это первое, что сканируют роботы Google
Если страница отмечена в файле robots.txt как запрещенная для сканирования, роботы не будут её сканировать и соответственно в индекс она не попадет.
Файл Sitemap.xml – это руководство для ботов Google
Файл Sitemap.xml помогает ботам понять, какие части сайта нужно просканировать и проиндексировать. Так как сайты в основном различаются по своей структуре, гуглбот не может краулить все страницы на сайте автоматически. Качественный файл Sitemap может помочь страницам с низким рейтингом, небольшим количеством обратных внутренних ссылок и бесполезным контентом попасть в индекс на равне с более авторитетными страницами.
Как оптимизировать сайт для лучшего сканирования поисковым роботом Googlebot?
Не недооценивайте файл robots.txt
Файл robots.txt является вместилищем команд для поисковых роботов. И так как ваш “краулинговый бюджет” ограничен, уделите время и постарайтесь закрыть от сканирования все необходимые страницы. Так, ваши самые ценные страницы будет индексироваться быстрее и чаще.
Полезный и уникальный контент действительно имеет значение
Основной тезис такой – контент, который сканируется чаще, ранжируется выше и соответственно приносит больше трафика. Особенно это становится важно сейчас. Google все больше ориентируется на новизну, актуальность страниц. Обновляйте контент на ваших топовых страницах, добавляйте их в индекс вручную и постепенно гуглбот будет сам уделять им больше внимания. Если у сайта слишком большое количество открытых страниц пагинации, то есть вероятность, что нужные вебмастеру страницы могут быть не проиндексированы. Это связано с тем, что поисковых бот израсходует краулинговый бюджет на продублированные страницы.
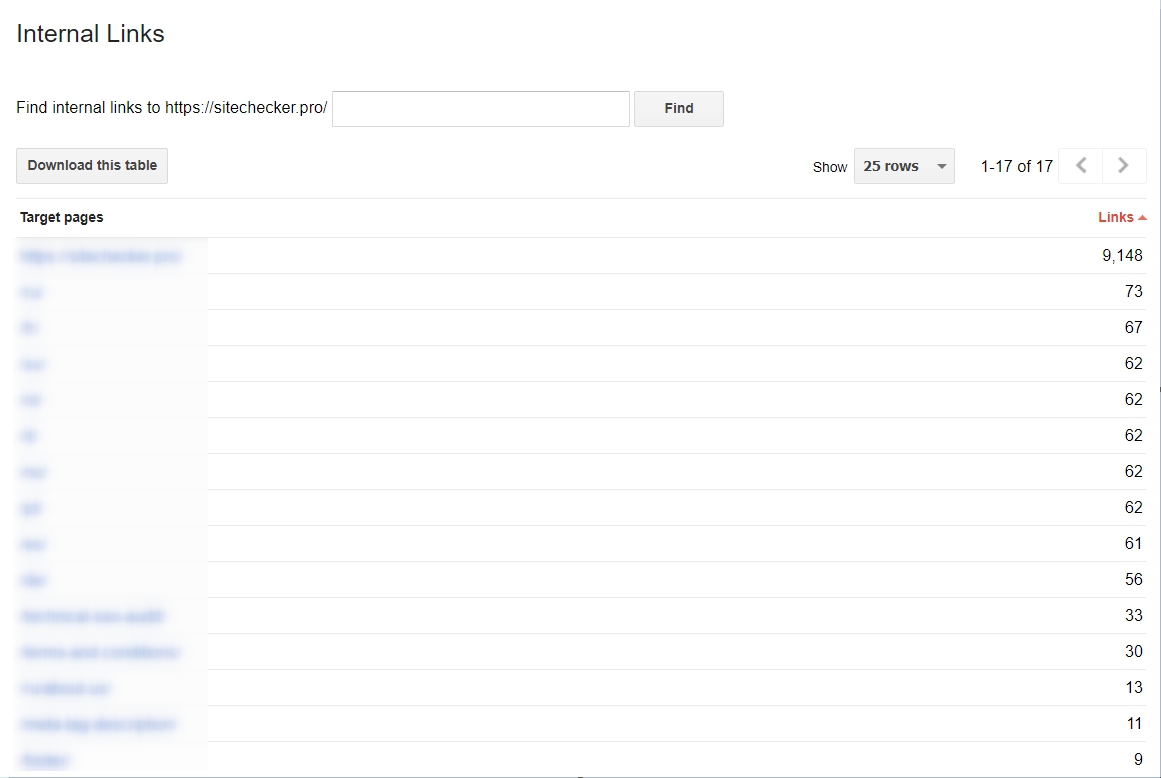
Пора начать использовать внутренние ссылки
Внутренние ссылки не только упрощают использование сайта для пользователя, но и делают проще процесс сканирования для поисковых ботов. Если ранее вы не уделяли внимания каждой ссылке на странице, воспользуйтесь Google Search Console, чтобы отследить активные ссылки. Для еще более глубокого исследования, добавьте ваш сайт в наш краулер и оцените всю структуру внутренних ссылок, анкор лист, распределение весов. Также вы можете попробовать запустить аудит сайта, чтобы найти ошибки и проанализировать внутреннюю структуру сайта, включаяя ссылки.
Sitemap.xml жизненно важен
Еще раз, почему этот файл так важен? Sitemap – это карта местности для бота. Без неё он блуждает по сайту только на основе внутренних ссылок, и страницы которые слабо перелинкованы получают мало внимания, или вообще могут быть не замечены. Это один из важных факторов, которые поисковая система гугл использует при сканировании сайтов.
Как анализировать работу Googlebot?
Для анализа работы гуглбота, просто регулярно проверяйте раздел «Сканирование» в Webmaster Tools.
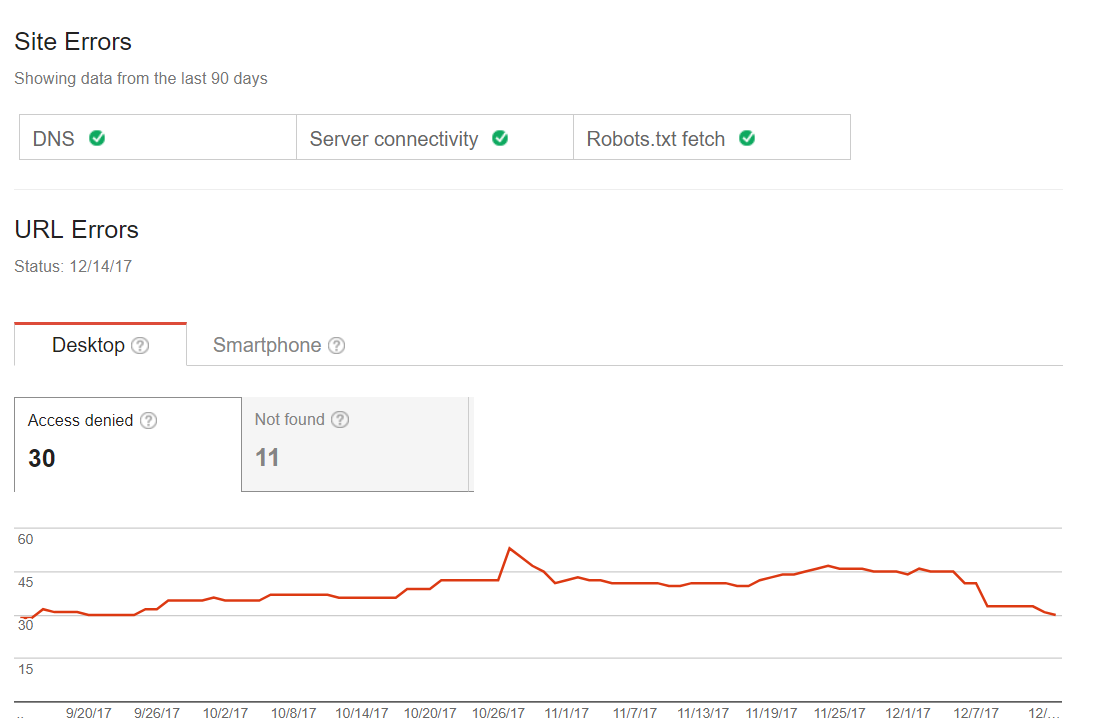
Популярные ошибки при сканировании
Страница “Ошибки сканирования” помогает быстро найти как критические ошибки, так и неопасные уведомления. К этому блоку чаще всего стоит обращаться, когда вы заметили какие то резкие изменения в индексации, снижение количества трафика.
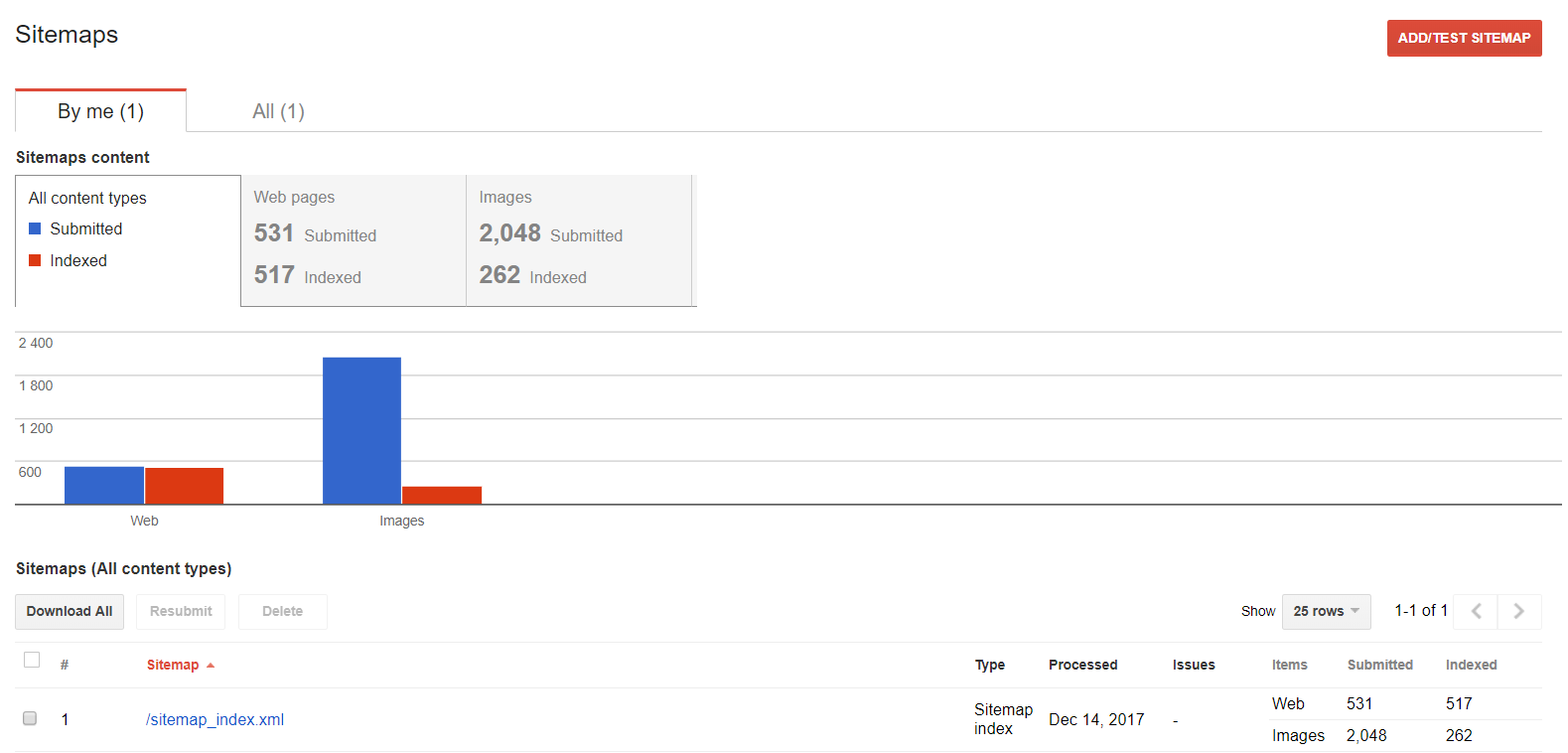
Файлы Sitemap
Используйте эту функцию, если хотите поработать с картой сайта: изучить, добавить или выяснить, какой контент индексируется.
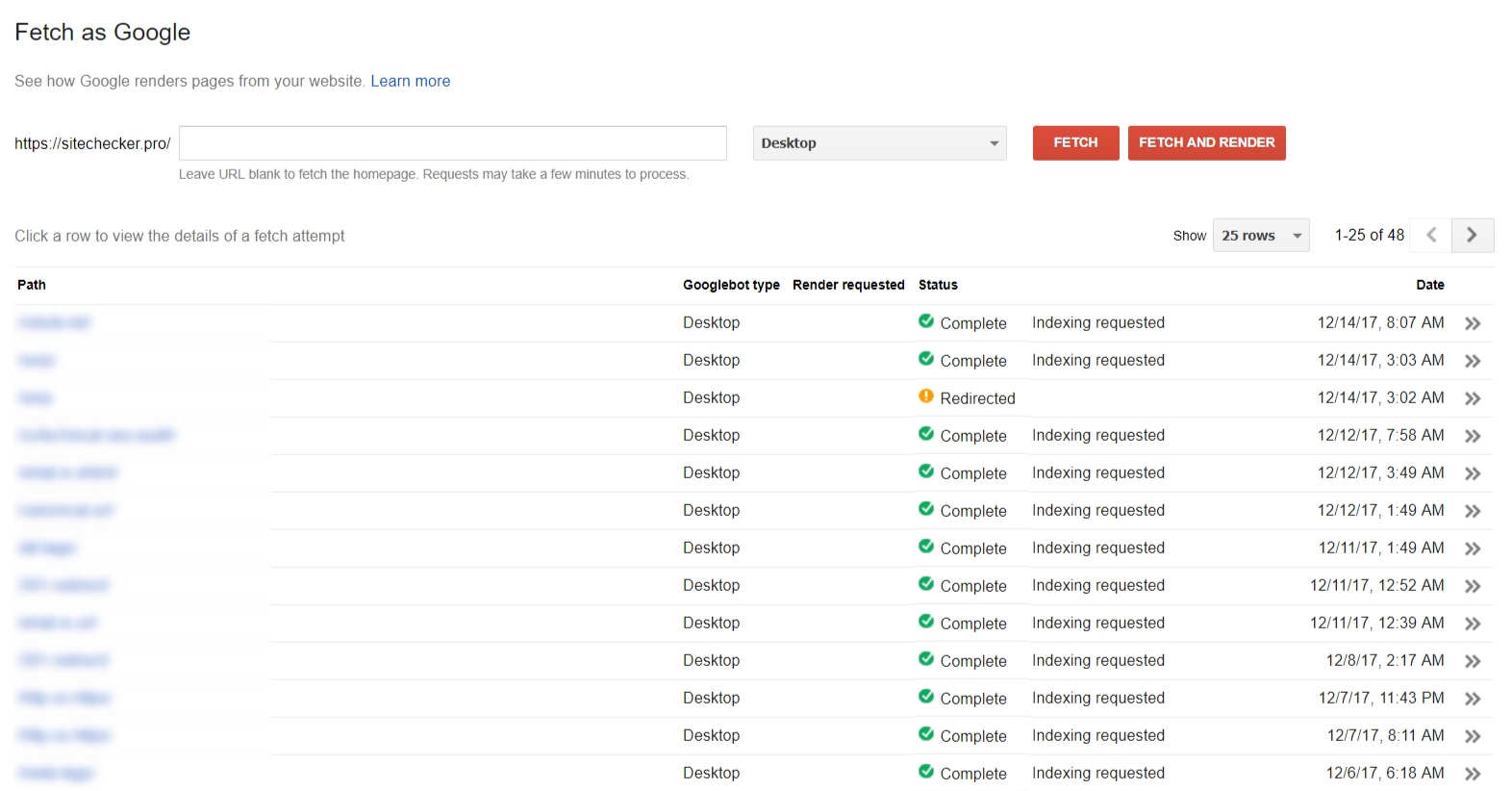
Посмотреть как Googlebot
Функция «Посмотреть как Googlebot» один из самых быстрых способов добавить страницу в индекс гугла.
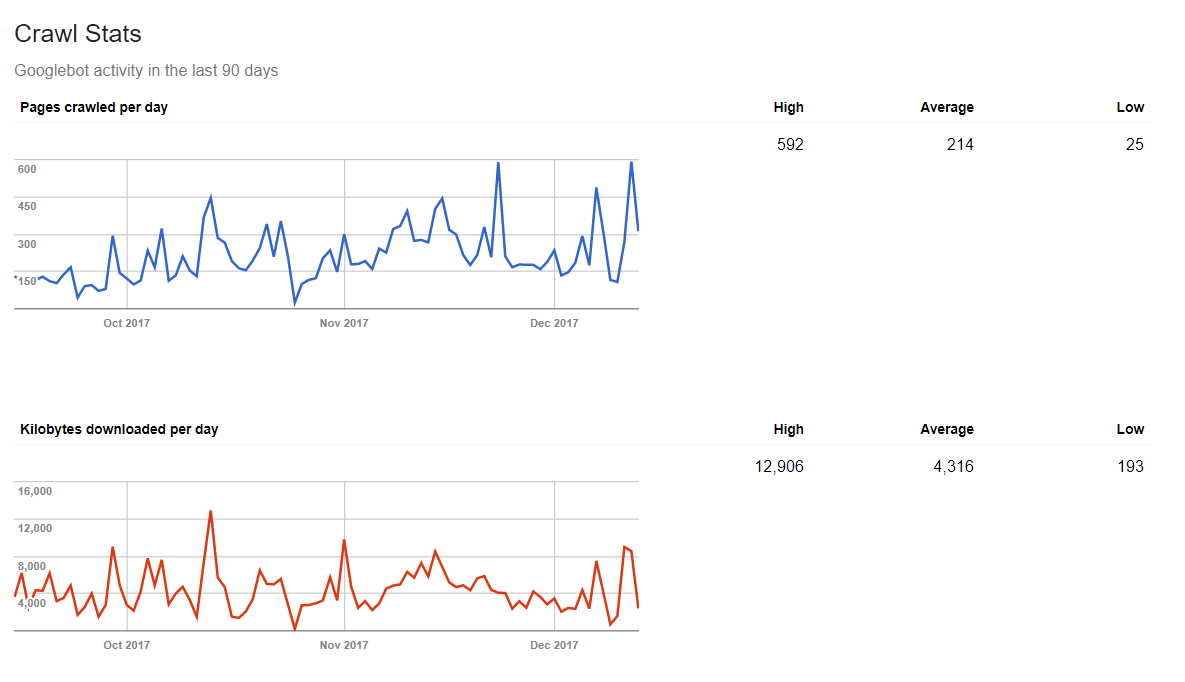
Статистика сканирования
Эта вкладка помогает оценить динамику сканирования сайта в разрезе 90 дней.
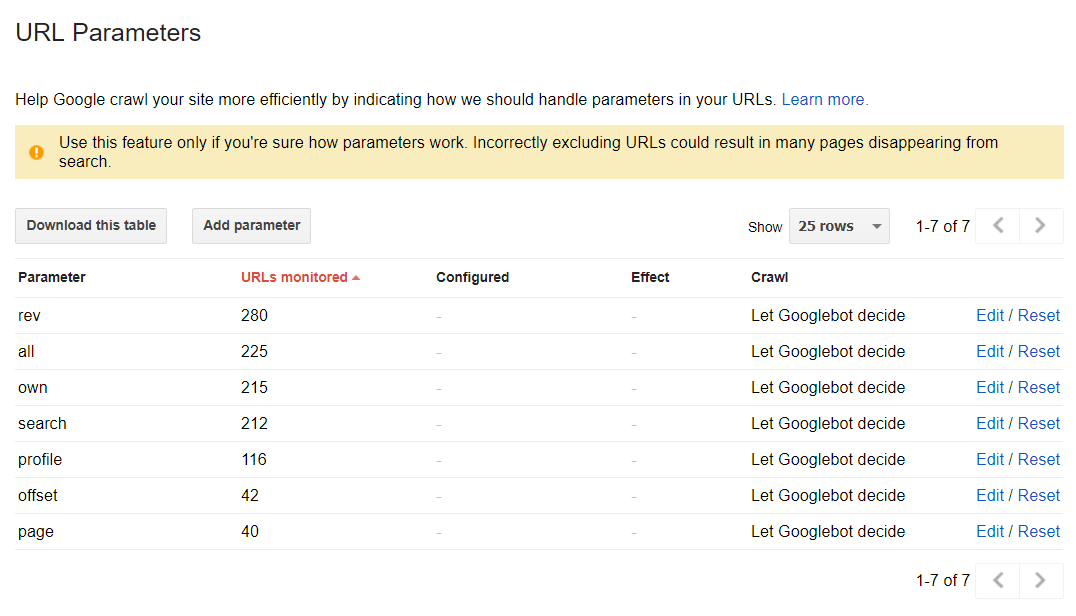
Параметры URL
Google не рекомендует использовать эту функцию без необходимости. По задумке, объяснение значений отдельных частей URL-адреса помогает гуглу лучше понимать как сканировать каждый тип страниц.