Vermutlich sind Sie mit den besten Praktiken rund um SEO vertraut: Sie haben gehört vom Wert der Website-Struktur, den Tag-Regeln, dem Einfügen von Schlüsselwörtern, dem Wert von einzigartiger Inhaltsoptimierung usw – dann haben Sie vielleicht auch von Google Bots gehört. Dennoch: Was wissen Sie über Google bots? Dieses Phänomen unterscheidet sich vom sehr bekannten SEO-Optimieren, weil es in einem tiefgründigen Level stattfindet. Während SEO Optimierung sich um die Optimierung des Texts für Suchmaschinen dreht ist Google Bot ein Prozess der Websiteoptimierung für Google Spiders. Natürlich sind diese Vorgänge nicht unähnlich. Aber lassen Sie uns den Unterschied zwischen den beiden erklären, weil die Auswirkungen auf Ihre Seite groß sein können. Hier sprechen wir von Phänomenen wie gut eine Seite zu durchsuchen ist – ein Hauptproblem, dem jeder Aufmerksamkeit schenken sollte, wenn es um die Suchbarkeit einer Seite geht.
Was ist Googlebot?
Site Crawler oder Google Bots sind Roboter, die eine Webseite erkunden und einen Index erzeugen. Wenn eine Website den Zutritt erlaubt, fügt der Bot die Seite zu einem Index hinzu und nur dann wird die Seite für einen User sichtbar. Wenn Sie sehen möchten, wie dieser Prozess abläuft, klicken Sie hier. Wenn Sie den Prozess der Googlebot-Optimierung verstehen wollen, müssen Sie klarstellen, wie genau der Google Spider die Site durchsucht. Hier gibt es die vier Schritte:
Wenn eine Webseite ein hohes Page-Ranking-Level hat, verbringt der Google Spider mehr Zeit damit, sie zu durchsuchen.
In dem Zusammenhang können wir von einem „Crawl-Budget“ sprechen, die der genauen Zeit entspricht, die ein Web Robot mit dem Scannen einer bestimmten Zeit verbringt. Je höher die Instanz einer Seite ist, desto mehr Aufmerskamkeit erhält sie.
Google Robots durchsuchen eine Website ständig
Hier ist, was Google darüber sagt: „Google Robot braucht eine Website nicht öfter betreten als einmal pro Sekunde.“ Das bedeutet, dass Ihre Website unter konstanter Überwachung durch Webspider ist, wenn diese Zugriff darauf haben. Heute sprechen viele SEO-Manager über sogenannte „Crawl-Rates“ und versuchen einen idealen Weg für das Crawling zu finden, damit die Seite einen sehr hohen Ranking-Level erreicht. Dennoch dürften wir feststellen, dass dies eine Fehlinterpretation ist, weil die „Crawl Rate“ nichts anderes ist als die Geschwindigkeit der Google Robot-Anfragen als die Crawling Wiederholung. Sie können diese Zahl selbst beeinflussen, indem Sie verschiedene Webmaster-Tools verwenden. Eine große Zahl und backlink check, eine Einzigartigkeit und soziale Erwähnungen beeinflussen Ihre Position bei den Suchergebnissen. Wir sollten auch erwähnen, dass Web Spider nicht alle Seiten konstant durchsuchen. Deshalb sind konstante Inhaltsstrategien sehr wichtig, ebenso die Einzigartigkeit und die Sinnhaftigkeit des Inhalts, die die Aufmerksamkeit von Bots auf sich zieht.
Die Datei Robots.txt ist das erste, was Google Robots untersuchen, um einen Plan für das Site Crawling zu bekommen
Das bedeutet, dass wenn die Seite als „unerlaubt“ in der Datei markiert ist, Robots nicht imstande sind, sie zu scannen und indizieren. Stellen Sie also sicher, dass Sie die robots.txt erstellt korrekt haben.
XML Sitemap ist ein Leitfaden für Google bots
Die XML Sitemap hilft Bots herauszufinden, welche Website-Orte zu durchsuchen und indizieren sind, weil es mögliche Unterschiede in der Struktur und Organisation der Website gibt. Eine gute Sitemap kann Seiten mit kleinem Ranking-Level, einigen Backlinks und sinnlosem Inhalt helfen, mit Bilden, News und Videos usw. besser umzugehen.
6 Strategien, wie Sie Ihre Site für das Crawling durch Googlebots optimieren können
Wie Sie jetzt wissen, muss die Optimierung durch den Google Spider gemacht werden, bevor Sie irgendwelche Schritte hinsichtlich SEO unternehmen. Deshalb lassen Sie uns erklären, was Sie tun sollten, um den Prozess der Indizierung durch Google Bots zu verbessern.
Übertreibungen sind nicht gut
Wissen Sie, dass Googlebots keine Frames, Flash, JavaScript, DHTML oder die bestens bekannten HTML scannen können? Mehr noch, Google hat noch nicht klargestellt, ob Googlebot imstande ist, Ajax und JavaScript zu crawlen. Somit sollten Sie dies besser nicht verwenden, wenn Sie Ihre Website erstellen. Obwohl Matt Cutts erwähnt, dass JavaScript für Webspider geöffnet werden kann, liefern Google Webmaster Guidelines folgende Information: Wenn solche Dinge wie Cookies, verschiedene Frames, Flash oder JacaScript nicht in einem Textbrowser gesehen werden, kann es sein, dass Web Spider nicht imstande sind, diese Website zu durchsuchen.“ Meiner Meinung nach sollte JavaScript deshalb nicht übermäßig benutzt werden.
Unterschätzen Sie nicht die Datei robots.txt
Haben Sie jemals über den Nutzen der Datei robots.txt nachgedacht? Es ist die allgemeine Datei, die in vielen SEO-Strategien verwendet wird. Aber ist sie wirklich sinnvoll? Erstens ist die Datei ein Wegweiser für alle Web-Spider. Also wird der Google Robot „Crawl-Budget“ auf jeder Webseite Ihrer Site verbringen. Zweitens sollten Sie für sich selbst entscheiden, welche Datei durch den Bot zu durchsuchen ist. Wenn es eine Datei gibt, die nicht gecrawlt werden dard, müssen Sie dies in Ihrer robots.txt festlegen. Warum ist das zu tun? Wenn es Seiten gibt, die nicht durchsucht werden sollen, wird der Google Bot das sofort sehen und diesen Teil der Seite durchsuchen, der wichtiger ist. Dennoch – meine Empfehlung schreibt nicht vor, was blockiert werden soll. Wenn Sie nicht angeben, dass etwas von der Suche ausgeschlossen wird, wird der Bot alles per Standard untersuchen und indizieren. Somit ist die Hauptfunktion der Datei robots.txt, zu instruieren, wo das Indizieren nicht funktionieren darf.
Nützlicher und einzigartiger Inhalt spielt wirklich eine Rolle
Die Regel besagt, dass Inhalt, der häufiger durchsucht wird, einen höheren Traffic bekommt. Neben der Tatsache, dass der PageRank die Crawl-Häufigkeit bestimmt, kann es sein, dass man mit Sinnhaftigkeit und Frische einer Website den ähnlichen PageRank erreicht. Somit sollten Sie versuchen, dass Ihre niedrig gereihten Seiten regelmäßig gescannt werden. AJ Kohn sagte einst: „Sie sind ein Gewinner, wenn Sie Ihre niedrig-gereihten Seiten in jene verwandeln, die häufiger gescannt werden als die konkurrierenden.“
Erhalten Sie magische Scroll-Seiten
Wenn Ihre Seite endlose, scrollbare Seiten enthält, bedeutet das nicht, dass Sie keine Chance auf Googlebot Optimierung haben. Somit sollten Sie sicher sein, dass diese website check die Google-Guidelines erfüllen.
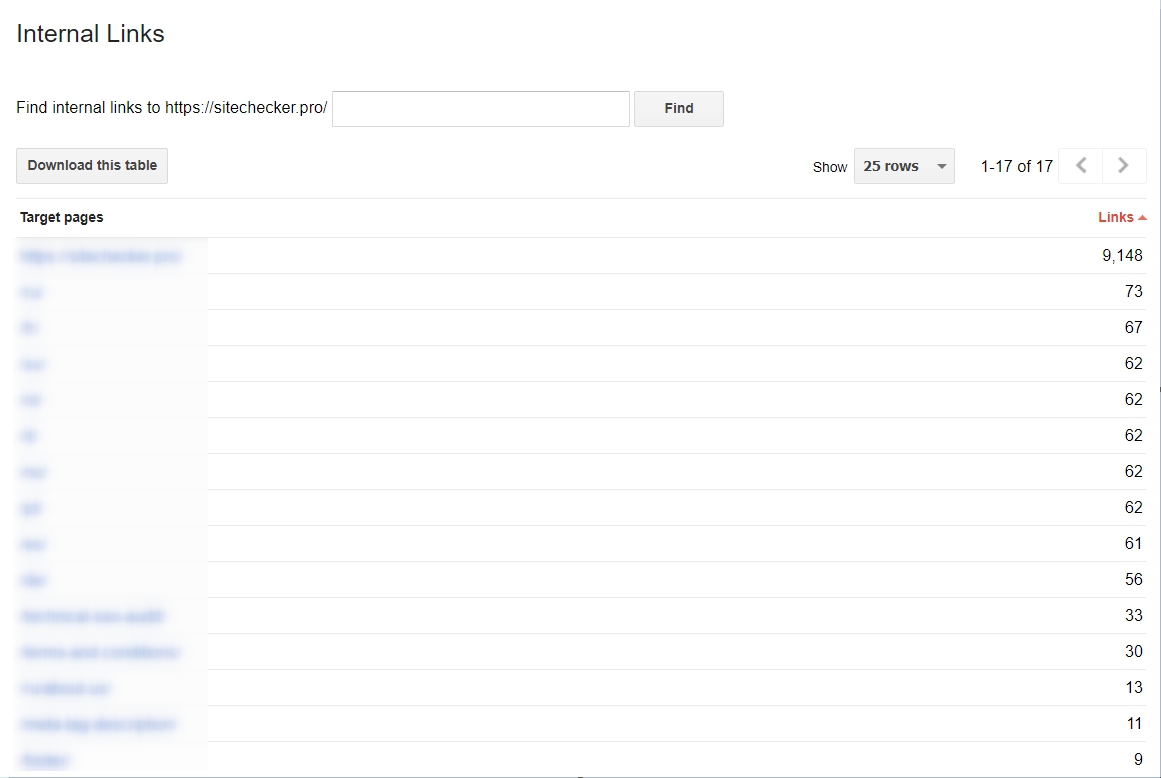
Sie sollten mit der Verwendung interner Links beginnen
Es ist sehr wichtig, sie zu verwenden, um den Suchprozess für Googlebots viel einfacher zu machen. Wenn Sie Ihre Links engmaschig und konsolidiert sind, ist der Suchprozess viel effektiver. Wenn Sie eine Analyse Ihrer internen Hyperlinks wollen, können Sie dies mit den Google Webmaster Tools tun. Dort wählen Sie „Search Traffic“ und wählen den Bereich „Interne Links“. Wenn Webseiten an der Spitze der Liste sind, beinhalten sie nützliche Inhalte.
Sitemap.xml ist vital
Die Sitemap gibt Googlebot die Richtung vor, wie es die Website durchforsten soll; Es ist ein einfacher Wegweiser. Warum ist dies involviert? Viele Websites sind heutzutage nicht gerade einfach zu scannen. Und diese Schwierigkeiten machen das Crawling teils ziemlich schwierig. In den Bereichen Irher Seite kann dies den Web Spider verwirren. Die Sitemap hilft, dass auch diese Bereiche durchsucht werden.
Wie analysiert man die Aktivität von Googlebot?
Wenn Sie sehen möchten, wie der Googlebot auf Ihrer Seite arbeitet, können Sie die Google Webmaster Tools verwenden. Zudem empfehle ich Ihnen, die Daten, die dieser Dienst anbietet, regelmäßig zu durchleuchten. Er zeigt, wenn irgendwelche Probleme beim Crawling auftreten. Einfach die „Crawl“-Bereiche in den Webmaster Tools checken, dann wissen Sie mehr.
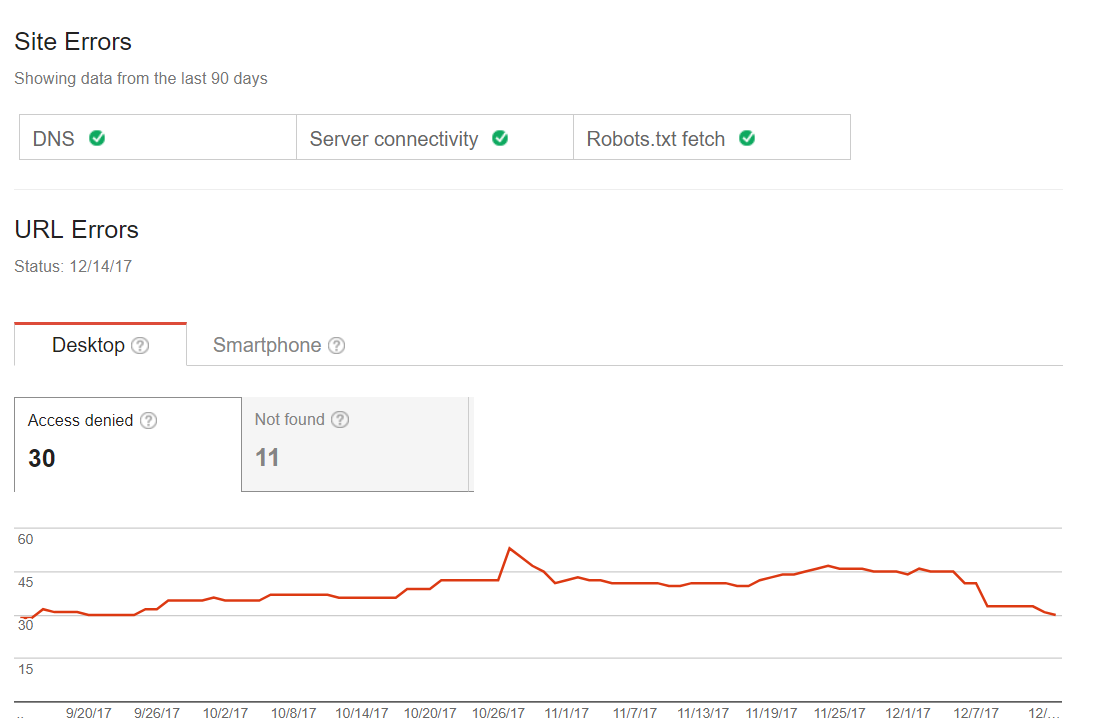
Allgemeine Fehler des Crawling
Sie können herausfinden, ob es bei Ihrer Seite mit dem Scannen Probleme geben wird. Sie würden entweder keine Fehler erwarten oder rote Fähnchen o.ä. sehen, z.B. Seiten, die man auf der letzten Index-Seite erwarten würde. Deshalb sollten sie im ersten Schritt über das nachdenken, wenn Sie Googlebot-Optimierungen vornehmen wollen. Manche Websites können kleinere Scanfehler aufweisen, aber das muss den Traffic nicht zwingend beeinflussen. Dennoch sollte man diese Probleme beheben, damit diese nicht irgendwann zu Trafficreduktionen führen. Hier finden Sie ein Beispiel einer solchen Site:
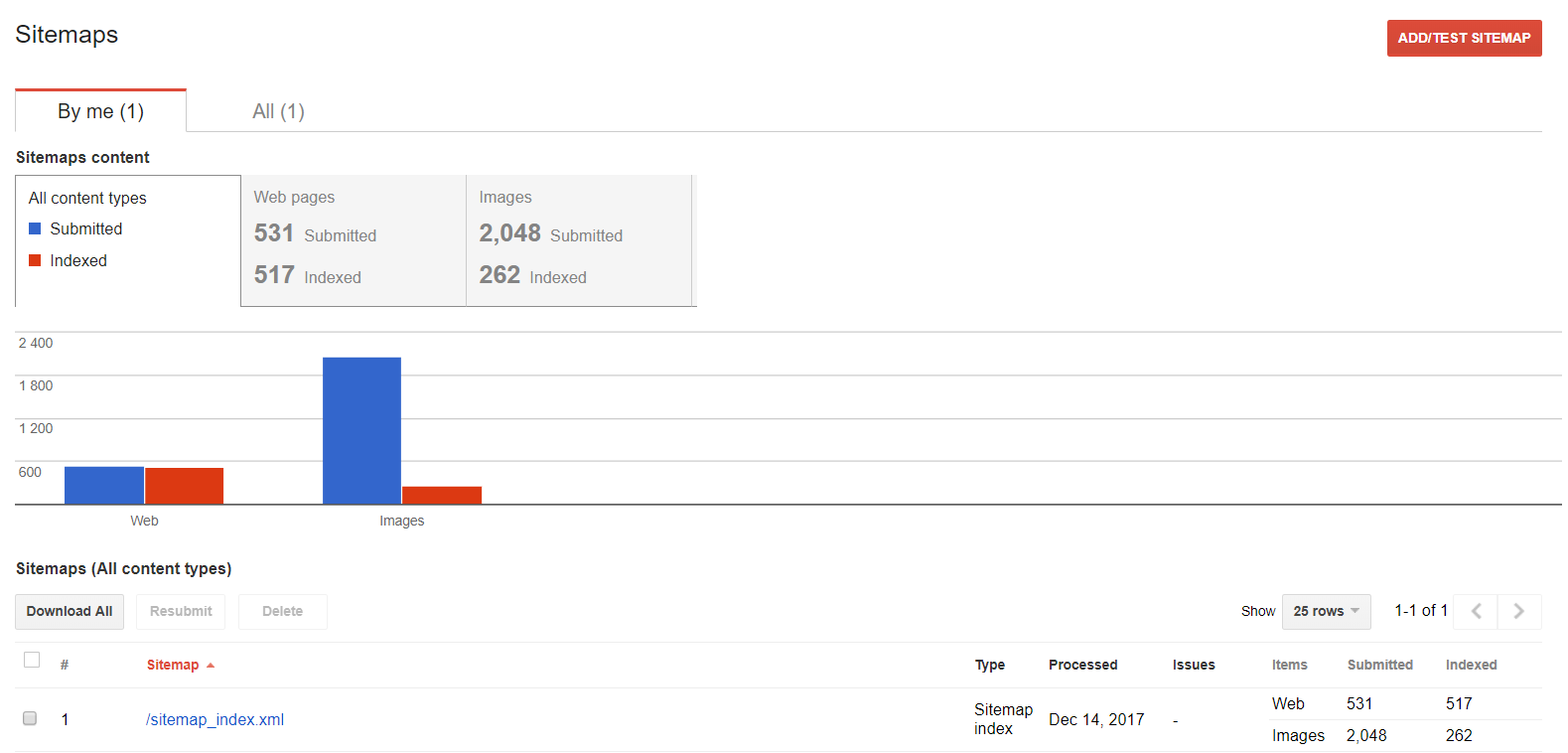
Sitemaps
Sie können diese Funktion verwenden, wenn Sie mit Ihrer Sitemap arbeiten wollen: prüfen sie, welche Inhalte indiziert werden.
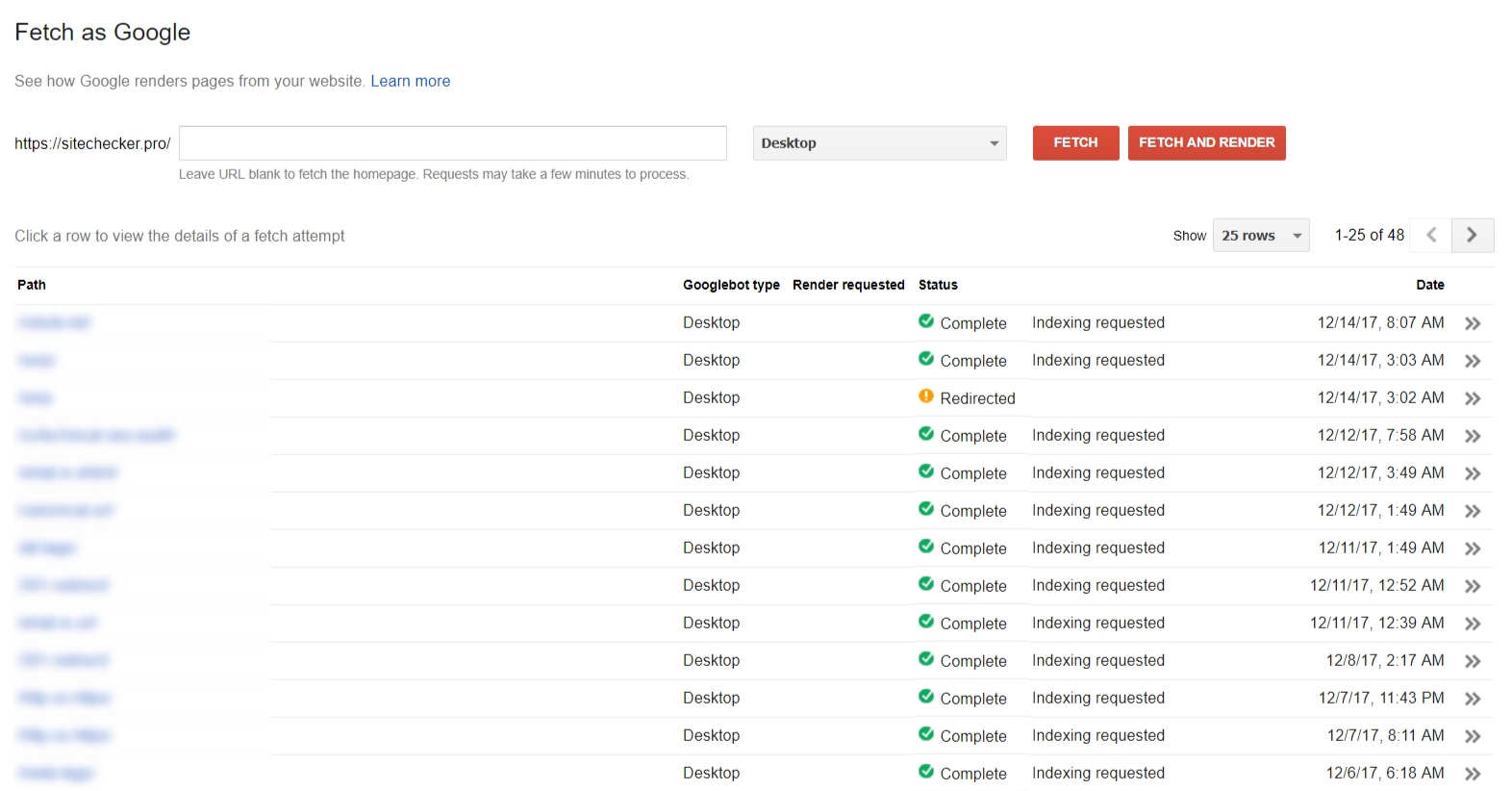
Fetching
Der Bereich “Fetch as Google” hilft zu sehen, wie Google Ihre Seite sieht.
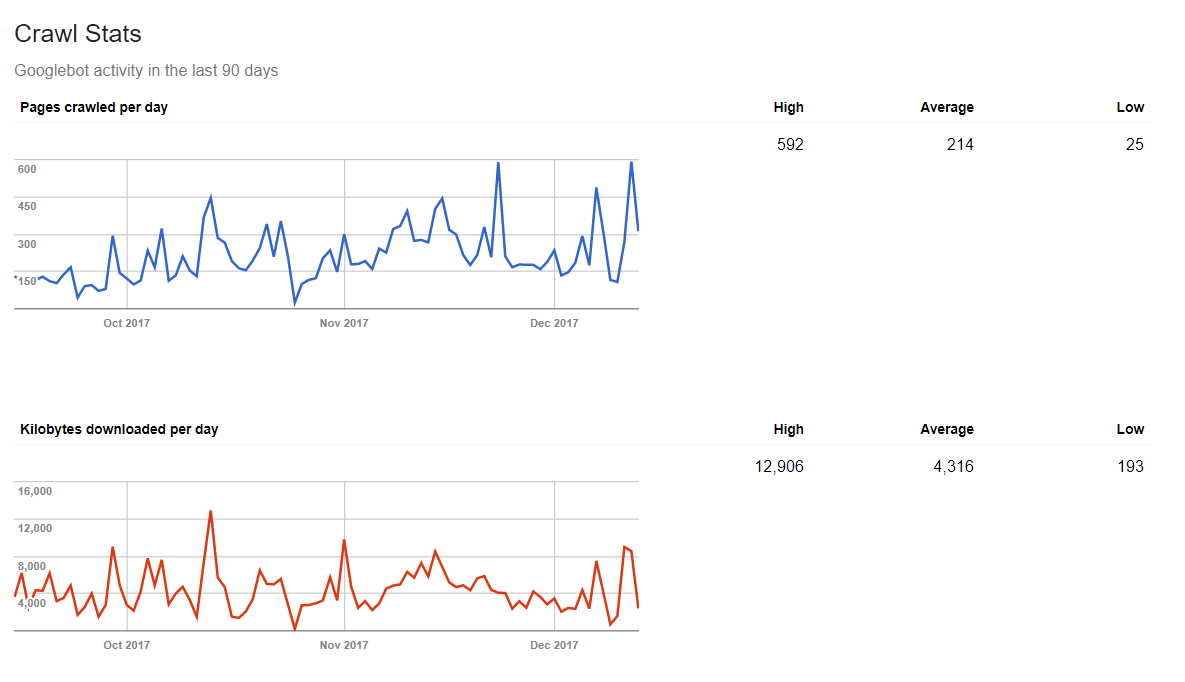
Crawling Statistics
Google kann Ihnen auch sagen, wie viele Daten der Webspiderprozess jeden Tag beansprucht. Wenn Sie täglich frische Inhalte veröffentlichen, bekommen Sie ein positives Ergebnis in der Statistik.
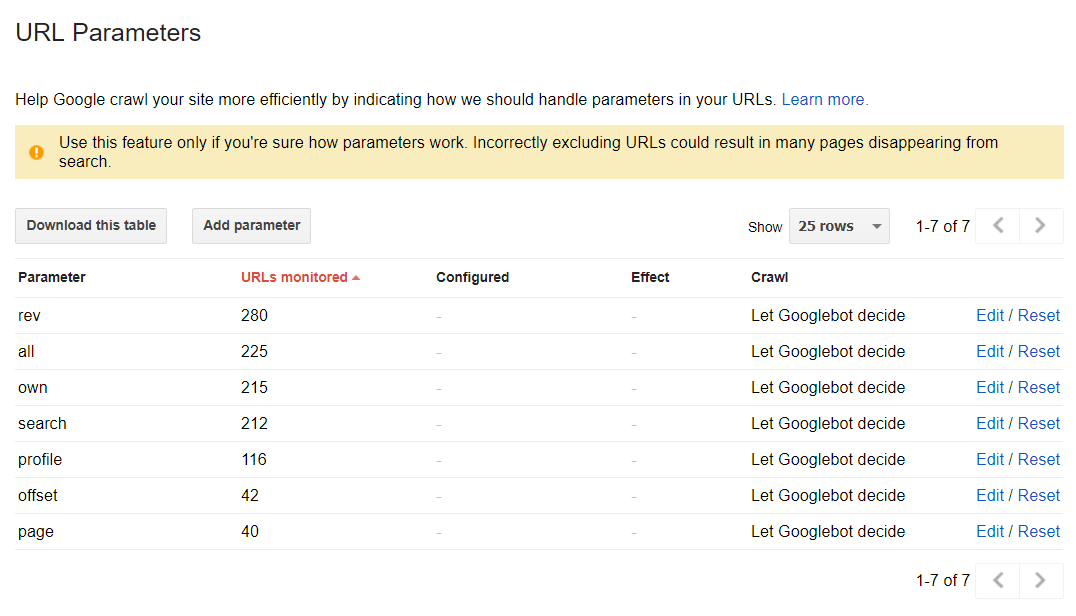
Die Paramter einer URL
Dieser Bereich kann helfen, herauszufinden, wie Google Ihre Website anhand der URL Parameter durchsucht und indiziert. Im Standard-Modus werden alle Seiten durch folgende Web Spider Entscheidungen durchsucht: